
Author Credit: Anita Kirkovska
.png) About Pylon
About Pylon
The Classification task
In our experiment, we compared GPT-3.5 Turbo, GPT-4 Turbo, Claude 2.1 and Gemini Pro to understand which one best identifies if a customer support ticket is resolved.
This initiative was inspired by our customer Pylon, a company that helps B2B companies to interact with their clients on apps they frequently use, like Slack.
Pylon was already running a classifier in production that identified resolved tickets, but they wanted to boost its accuracy. To achieve this, we evaluated different models and prompting techniques to identify the most accurate approach for their use-case.
During the course of this experiment, we realized that the lessons we were learning could benefit all LLM users because classification is such a common use of LLMs.
Today, we're excited to share these insights with everyone, and we hope they prove to be a valuable resource.
Why is this a difficult task
Well, customer conversations can be tricky to classify. Mostly due to the variability in language, nuanced context, and evolving dialogues.
Edge cases
Handling specific edge cases further complicates the process.
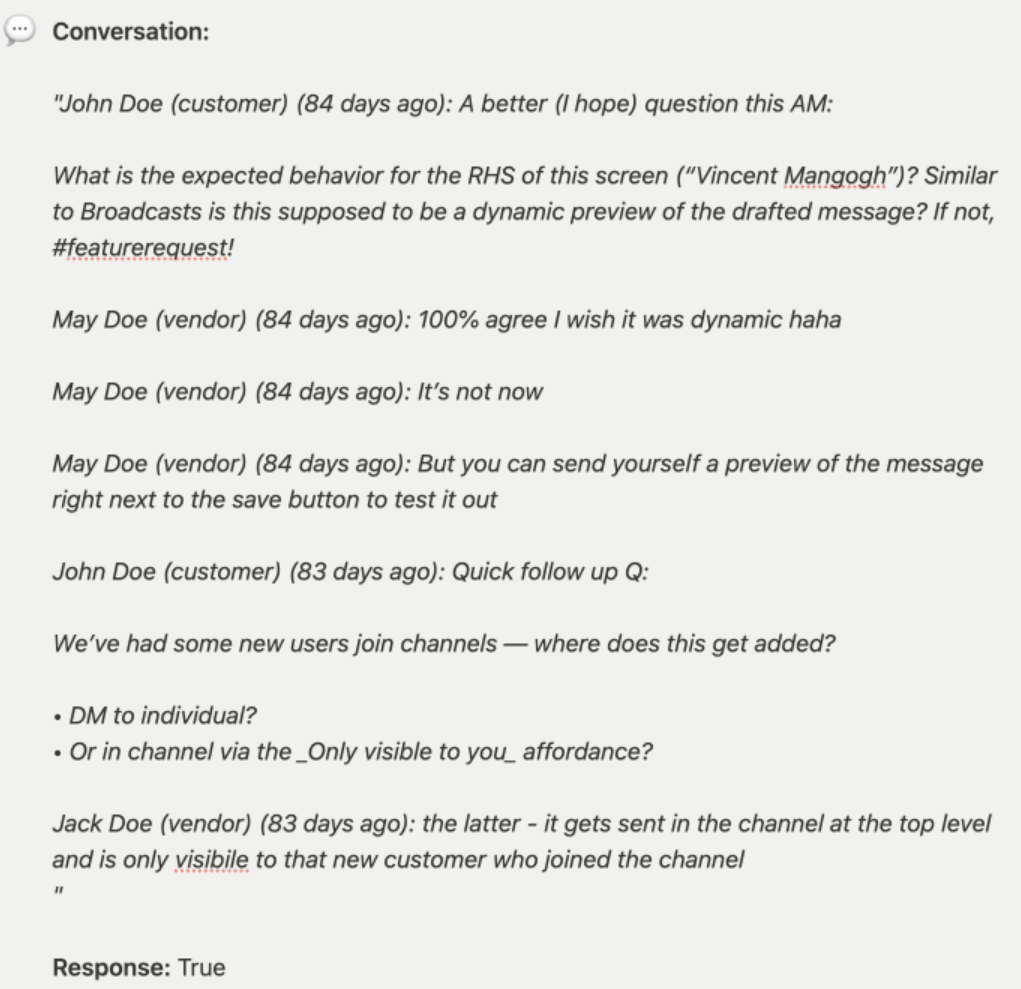
For instance, if a vendor replies to a bug report by acknowledging that it’s a known issue, the ticket is considered resolved even though the bug isn’t. However, without the proper guidance, the language model may not always recognize this.
Here’s an example of such conversation, that’s marked as resolved:

Customizing Prompts
Different models may show improved performance with minor modifications to the prompts. Figuring out which prompts work best for each model is a subtle and intricate process.
Sometimes the examples you use in few-shot prompting can confuse the model if the examples aren’t the best representation of the expected data in production. This can be particularly problematic for customer tickets, as there is high level of variability in the language and content.
Overfitting / Imbalanced datasets
You also need to look at recall and precision even when your accuracy is high, to understand if you’re overfitting the model to specific examples in cases when you’re dealing with imbalanced datasets.
Evaluating the models
We compared four models based on their accuracy, recall, and precision across 200 test cases. It’s worth noting that Pylon had more than 10,000 data points, but for this experiment, we manually labeled 200 examples to get good ground truth data.
These metrics are important for classification tasks because it's essential to correctly identify true cases, accurately dismiss false ones, and reduce the number of incorrect guesses.
By looking at all three, we can really tell how good these models are at this job.
Results
Here’s what we learned:
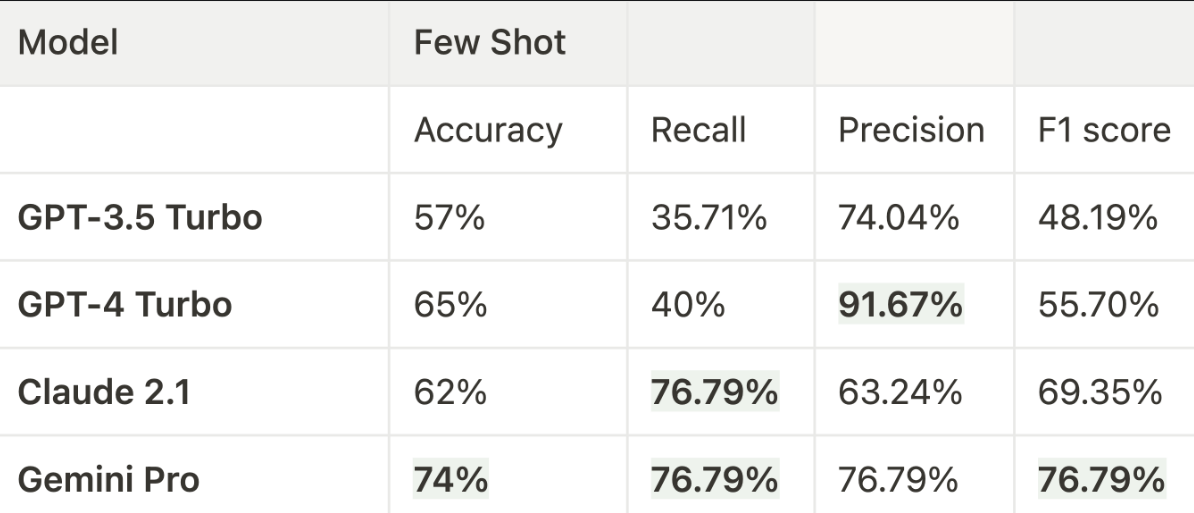
- Gemini Pro has the highest overall performance across all metrics. It outperformed all other models on all metrics with accuracy at 74%, and an F1 score at 76.69%. Its balanced performance suggests it is equally good at identifying true positives and avoiding false positives.
- Claude 2.1 has a high recall of 76.79%, indicating it is good at identifying resolved tickets but has a lower precision of 63.24%, meaning it has a higher rate of false positives compared to Gemini Pro. Its F1 score is high at 69.35%, which is the second-best, showing a good balance between precision and recall.
- GPT-4 Turbo shows a high precision of 91.67%, indicating it is very accurate when it identifies tickets as resolved, but it might be too conservative. Its recall is the second lowest at 40%, suggesting that while its predictions are accurate, it misses many resolved tickets. The low F1 score of 55.70%, reflects the imbalance between its high precision and low recall.
- GPT-3.5 Turbo has the lowest accuracy of all models at 57%. With a recall of 35.71%, it indicates a significant number of resolved tickets are being missed. Its precision is relatively better at 74.04%, but still lower than GPT-4 Turbo and Gemini Pro. The F1 score is the lowest at 48.19%, indicating it is not as effective in balancing precision and recall compared to the other models.

Which model is best for text classification?
In the context of customer support tickets, especially when determining if an issue has been resolved, recall takes precedence as the more important metric. This is because missing a resolved ticket might mean a customer's issue is overlooked and not addressed in a timely manner, leading to customer dissatisfaction.
If your goal is to classify tickets with a focus on increasing recall, you might opt for models like Claude 2.1 or Gemini Pro.
However, for other use-cases like medicine diagnosis, spam filtering or content moderation you should be looking at having high precision where the the cost of a false positive — an incorrect positive prediction — is high. In that case, the model with the highest precision should be your #1 choice.
Keep reading for more details on our methodology and the details of the experiment.
Methodology
Technical setup
For this comparison we used Vellum’s suite of features to manage various stages of the experiment. We used:
- Prompt Sandbox: To compare models & prototype prompts
- Test Suites: To evaluate hundreds of test cases in bulk and measure which cases fail
The dataset we used had 200 test cases. Here is an example:
Prompt engineering & techniques
Before testing the models, we experimented with different prompts to ensure that the models would only output "true" or "false" as answers, without adding any additional explanation. We used few-shot prompting for our evaluation, and included examples of resolved conversations and the format for the expected answers.
Here’s a snapshot on how that looked like in Vellum:

Once we were happy with the results on a few test cases, we ran the models on a larger set of cases.
Model Information
We decided to test the three top performing models - OpenAI's GPT-3.5, GPT-4 Turbo, Anthropic's Claude 2.1, and Google's newly released Gemini Pro using the above prompt
All models had 0 temperature, because we wanted to get to a well defined answer.

We should also note that Gemini Pro, while part of the Gemini model suite, is not the most advanced model in the series (Gemini Ultra is supposed to be more capable). However, it was the only model from the suite available to us for this comparison.
Setting up the test cases
To evaluate the models, we uploaded Pylon's dataset into a Test Suite (which is our unit testing product for LLMs) ****and selected "Exact Match" as the metric for evaluation.
This evaluation metric verifies if the LLM's output perfectly matches the expected dataset output, considering any extra whitespaces the model might generate. Given that we anticipated either a "true" or "false" output, the evaluation process was straightforward.
Using Test Suites we were able to run all of these test cases at scale.
Running the evaluation
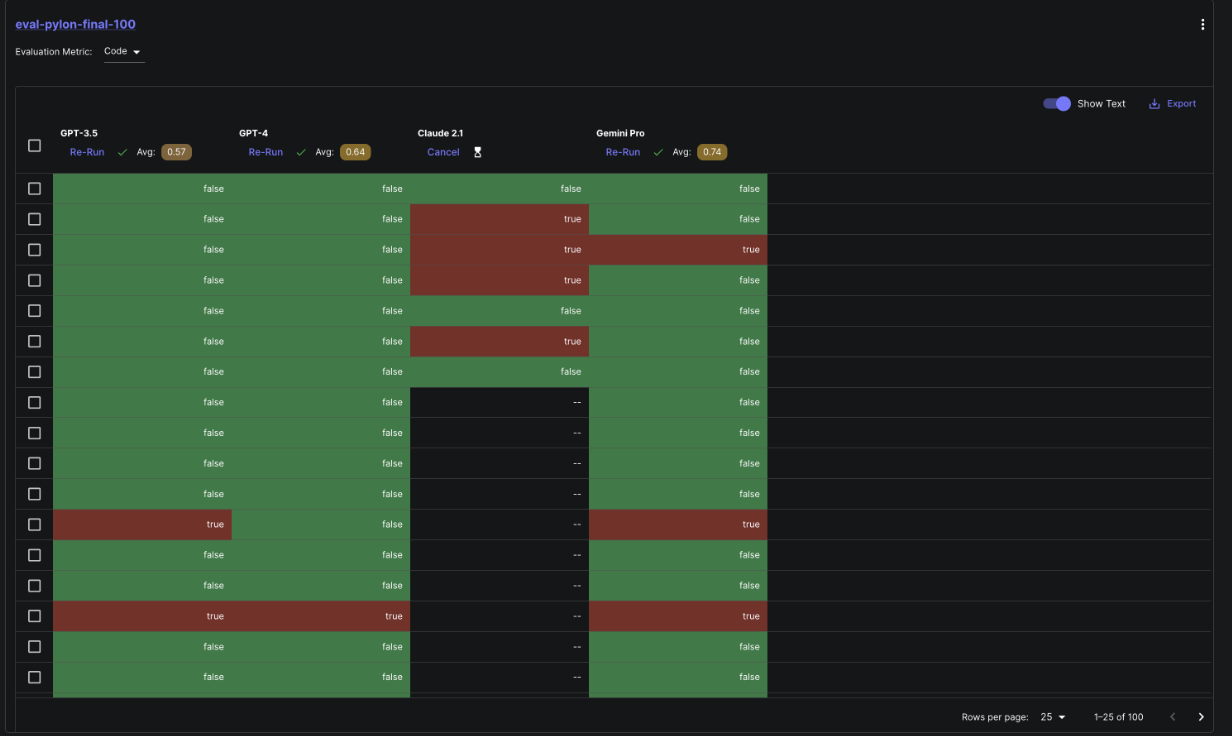
At this point we had our prompts and model configurations, and we were ready to run the prompt across our test cases.
We connected the Test Suite with our prompts and initiated the model runs. Here's what the setup looked like during the evaluation process:
Measuring the results
For this experiment, given that it’s a classification task we compared the models on three metrics: accuracy, recall and precision.
Here are the final results that we got on each of the model comparisons:
Conclusions and Observations
With this experiment, we assisted Pylon in reaching a 74% accuracy rate with few-shot prompting in their classification task using Gemini Pro. In addition to this, we observed that Gemini Pro is good at figuring out if customer problems were solved, with the best recall rate of 76.69%.
Claude2 also displayed a high recall rate, and can be a good alternative for classification tasks. GPT-4 showed the highest precision, making it a great choice for tasks where precision is crucial.
If you’re looking to scale your customer support operations using LLMs and want to evaluate different models and prompting techniques, we can help.
Vellum has the tooling layer to experiment with prompts and models, evaluate their quality, and make changes with confidence once in production.
You can take a look at some of our other use-cases, or book a call to talk with someone from our team, and we’d be happy to assist you.
Future work and Areas for improvement
As a logical next step, we plan to try other examples in the prompts, to understand why GPT-4 and GPT-3.5 weren’t able to generalize as well as Gemini Pro. We also think that fine-tuning a model using the dataset derived from Pylon's classifier data will probably give the best performance and reliability because it will potentially capture all nuances of this data.



